[Tech Blog] Unlocking the Potential of Few-Shot Learning through PatchCore Optimization
1. Introduction: The Barrier of “Large Amounts of Normal Data” That Hinders the Field
In the world of AI, there has long been a maxim: “Data is King.”
However, in manufacturing environments where defects appear only once every several thousand products, or in frontline medical settings dealing with rare cases, this maxim has effectively amounted to a death sentence for automation.
The long-held belief—
“High-accuracy anomaly detection requires at least several hundred normal samples”
was overturned by a groundbreaking approach that won 1st place in the CVPR 2023 VAND (Visual Anomaly Detection) Challenge.
This article unpacks the strategy that enables performance surpassing state-of-the-art algorithms using only 1–10 normal images.
Title: Optimizing PatchCore for Few/many-shot Anomaly Detection
https://arxiv.org/abs/2307.10792
2. Surprising Fact #1: “Optimizing Existing Models” Beats Creating New Algorithms
While many researchers race to develop complex, few-shot-specific methods, this study arrives at a strikingly clear conclusion:
Simply optimizing PatchCore, a method already well established for full-shot (large-data) settings, is enough to outperform the latest specialized models.
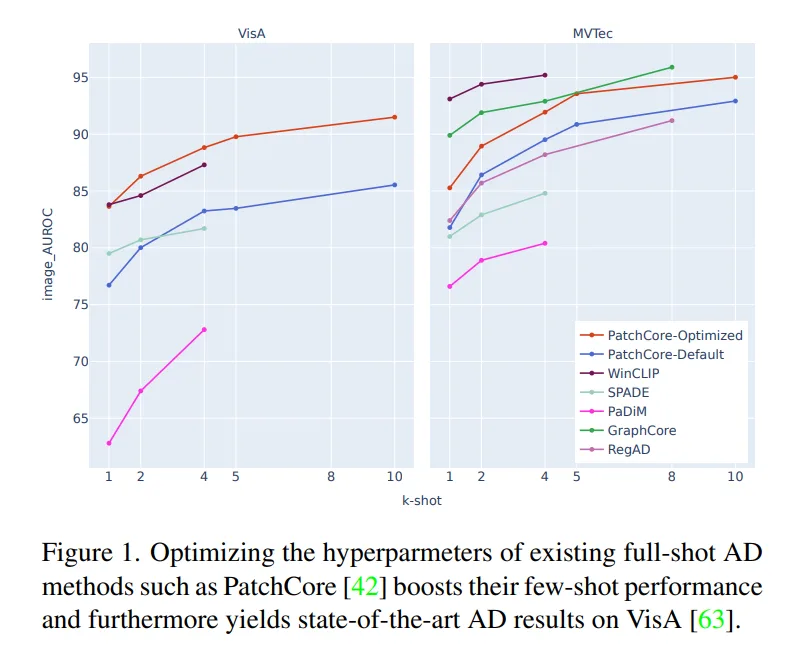
Rather than reinventing the wheel, the authors demonstrate that sharpening an existing masterpiece to withstand the extreme conditions of few-shot learning is the fastest path to practical success.
This work proves that hyperparameter optimization—not algorithmic novelty—is often the shortest route to deployment.
“Optimizing the hyperparameters of existing full-shot AD methods such as PatchCore boosts their few-shot performance and furthermore yields state-of-the-art (SOTA) results on VisA.”
3. Surprising Fact #2: Strong ImageNet Models Are Not Always Best for Anomaly Detection
The common assumption that
“Models with higher ImageNet classification accuracy make better anomaly detectors”
does not necessarily hold in the few-shot regime.
Experiments show that WideResNet-based models, one generation older, achieve the highest peak scores—outperforming newer architectures such as ConvNeXt and EfficientNet.
However, this comes with an important nuance engineers should not overlook: a trade-off between peak performance and stability.
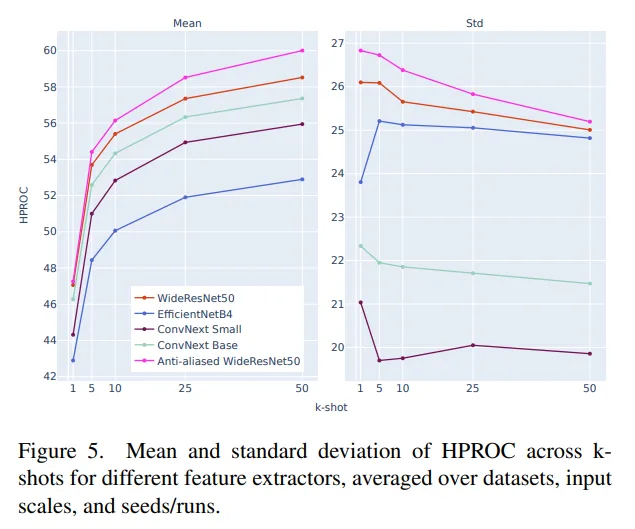
- WideResNet family: Achieves the highest accuracy under specific conditions (peak scores).
- ConvNeXt family: Slightly lower peaks, but more stable and consistent performance across varying shot counts and input scales.
“General-purpose features” and “features sensitive to subtle anomalies” are not the same.
Practitioners must strategically choose between absolute peak accuracy and robust stability, depending on the application.
4. Surprising Fact #3: Constraints Make Models Stronger — The Power of Anti-Aliasing
The fewer the training samples, the more likely an AI model is to mistake noise for “normality.”
The key to mitigating this risk is deliberately imposing constraints (inductive bias) on the model.
The most noteworthy finding in this study is the overwhelming effectiveness of anti-aliased models.
Modern CNNs often lose translation equivariance—the ability to respond consistently to positional shifts—due to aggressive subsampling.
Anti-aliasing restores these essential geometric properties.
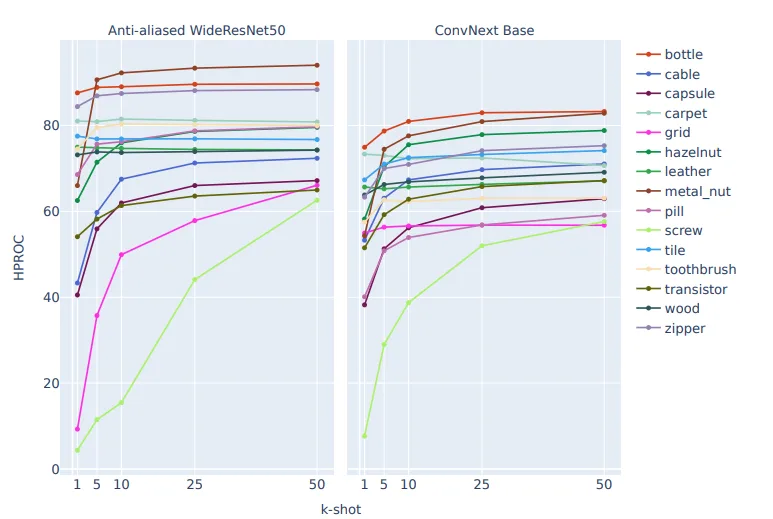
- Translation equivariance & invariance: Recovered through anti-aliasing.
- The power of a single image: With these constraints, the model can efficiently learn that “slightly shifted objects are still normal,” even from just 1–5 images.
5. Surprising Fact #4: Resolution Offers More Than Just Computational Cost
Increasing image resolution raises computational load, but in few-shot learning, the return far outweighs the cost—especially when defects are extremely small.
On the VisA dataset, where defect sizes are tiny, higher resolution produces dramatic gains.
The study adopts HPROC, the harmonic mean of Image-AUROC and Pixel-AUPR, as the evaluation metric.
Pixel-level evaluation uses AUPR to properly reflect the severe class imbalance where anomalous pixels occupy only a minute fraction of the image.
Performance gains (HPROC) relative to baseline resolution (1.0×):
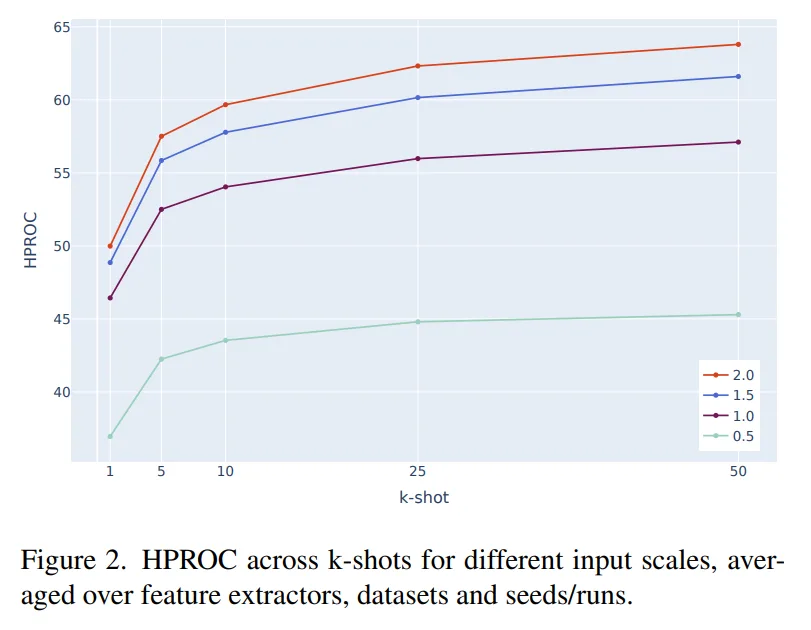
- 0.5×: Significant accuracy drop; fine anomaly details are lost.
- 1.5×: Stable and consistent improvements.
- 2.0×: +7.5 on VisA, +5.0 on MVTec AD.
Because VisA’s median defect size (0.002) is far smaller than that of MVTec AD (0.037), doubling the resolution becomes an absolute requirement to prevent missed detections.
6. Surprising Fact #5: Data Augmentation Is a Double-Edged Sword
While data augmentation is a standard technique in few-shot learning, in anomaly detection it can be harmful if not guided by domain knowledge.
- The trap of rotation and flipping:
For electronic components such as transistors, being upside down is itself an anomaly. Blindly applying flip augmentation teaches the model that critical defects are “normal.” - Specific failure cases:
On MVTec AD, applying sharpening augmentation was shown to reduce performance. - Vulnerability to rotation:
Even optimized PatchCore struggles with categories like screw (MVTec AD) or macaroni2 (VisA), where normal data already contains strong rotational variation.

CNNs are not inherently rotation-equivariant.
As a result, while PatchCore is robust to positional shifts, it remains fundamentally weak against rotation.
7. Conclusion and Outlook
This research demonstrates that by applying proper optimization and geometric constraints via anti-aliasing to PatchCore, one can achieve state-of-the-art performance in the notoriously difficult setting of few-shot anomaly detection.
The next major challenge lies in overcoming the revealed weakness to rotation.
Future anomaly detection systems are likely to evolve toward models with stronger physical constraints, such as rotation-equivariant CNNs.
“With only a handful of images, how close can we get to perfect quality control?”
The answer may lie not in inventing entirely new algorithms, but in uncovering the hidden potential of the tools we already possess.

