[技術ブログ] データが少なくても「異常」は見抜けるか?
PatchCore最適化が解き放つ少数学習の可能性
1. 導入:現場を阻む「大量の正常データ」という壁1. 導入:現場を阻む「大量の正常データ」という壁
AIの世界では古くから「データこそが王様(Data is King)」という掟があります。しかし、欠陥品が数千回に一度しか現れないような製造現場や、希少な症例を扱う医療の最前線において、その掟は自動化への「死刑宣告」に等しいものでした。
「高精度な異常検知には、少なくとも数百枚の正常データが必要である」——この常識を打ち破ったのが、CVPR 2023のVAND(Visual Anomaly Detection)チャレンジで1位を獲得した画期的なアプローチです。本記事では、わずか1〜10枚の「正常画像」から、最新アルゴリズムを凌駕する精度を叩き出すための戦略を解き明かします。
タイトル:Optimizing PatchCore for Few/many-shot Anomaly Detection
https://arxiv.org/abs/2307.10792
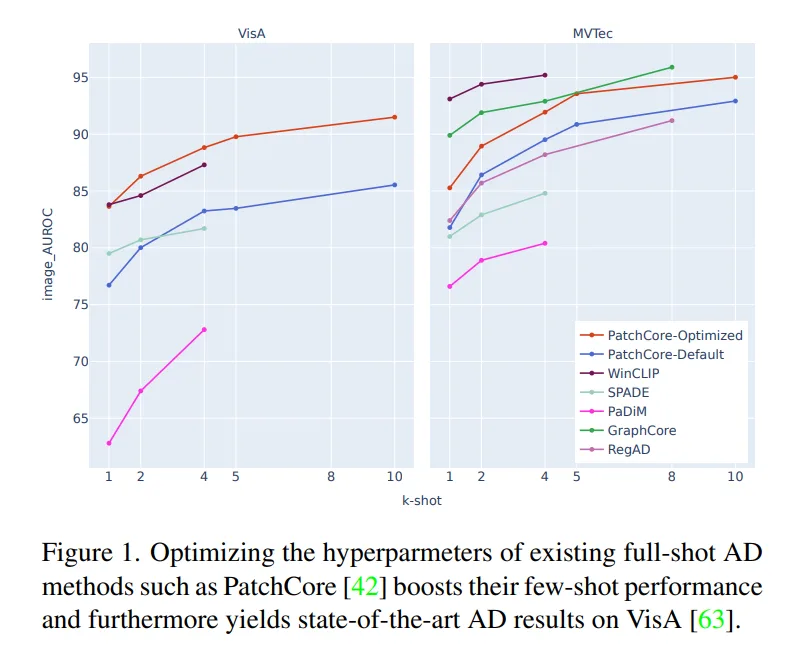
2. 驚きの事実1:新しいアルゴリズムよりも「既存モデルの最適化」が勝る
多くの研究者が少数学習(Few-shot)専用の複雑な新手法を開発しようと凌ぎを削る中、本研究が示した結論は痛快なものでした。それは、すでにフルショット(大量データ学習)向けに定評のある「PatchCore」を適切に最適化するだけで、最新の専用モデルを凌駕できるという事実です。
車輪を再発明するのではなく、既存の傑作を「少数学習」という極限環境に合わせて研ぎ澄ます。この「ハイパーパラメータの最適化」こそが、実務における最短ルートであることを証明したのです。
"Optimizing the hyperparmeters of existing full-shot AD methods such as PatchCore boosts their few-shot performance and furthermore yields state-of-the-art (SOTA) results on VisA."
3. 驚きの事実2:ImageNetの成績が良いモデルが、異常検知に強いとは限らない
「ImageNetでの画像認識精度が高いモデル(特徴抽出器)ほど、異常検知でも優秀である」というこれまでの定説は、少数学習の文脈では必ずしも当てはまりません。
実験では、最新の「ConvNext」や「EfficientNet」を抑え、一世代前の「WideResNet」系モデルが最高のピークスコアを記録しました。ただし、ここにはエンジニアが注目すべき「安定性とピークのトレードオフ」という重要なニュアンスが隠されています。
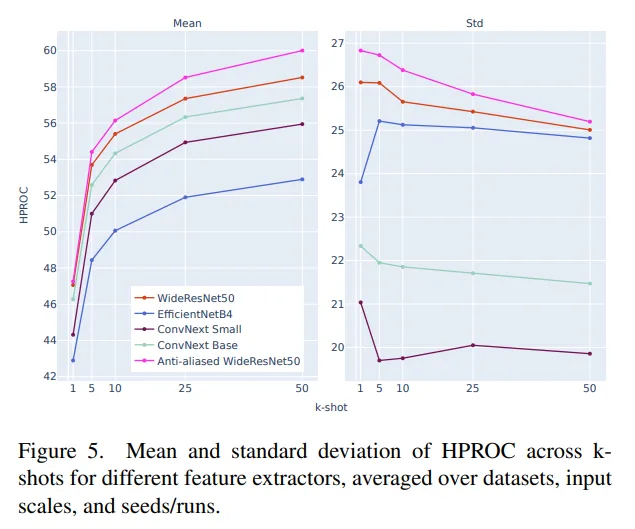
- WideResNet系: 特定の条件下で最高の精度(ピークスコア)を叩き出す。
- ConvNext系: ピークは一歩譲るものの、データの数(ショット数)や入力スケールの変化に対して、より安定した一貫性のあるパフォーマンスを発揮する。
「汎用的な特徴量」と「微細な異常を見抜くための特徴量」は別物であり、用途に応じて安定性を取るか、絶対的な精度を取るかの戦略的選定が求められます。
4. 驚きの事実3:「制約」がモデルを強くする:アンチエイリアシングの力
データが少ないほど、AIはノイズを「正常さ」の一部だと勘違いしやすくなります。このリスクを抑える鍵は、モデルにあえて「制約(帰納バイアス)」を与えることです。
本研究で最も注目すべきは、「アンチエイリアス処理済みモデル」の圧倒的な有効性です。 現代のCNN(畳み込みニューラルネットワーク)は、過度なサブサンプリングによって「移動等変性(Translation Equivariance)」という、画像内の位置変化に柔軟に対応する性質を失いがちです。
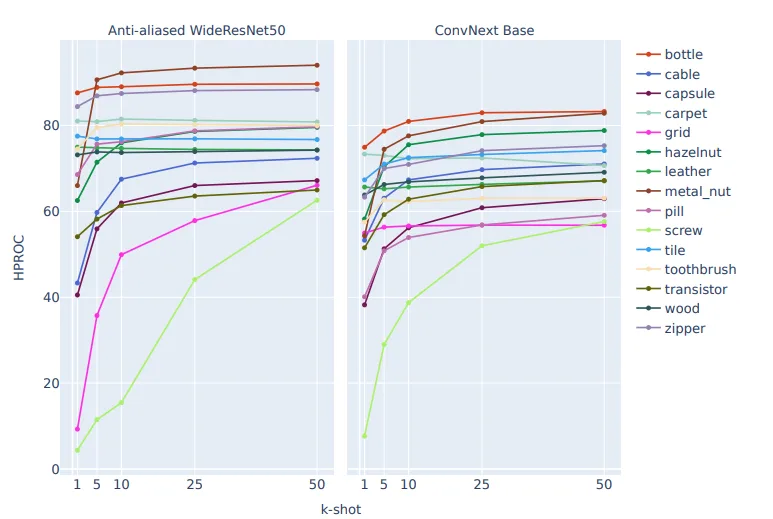
- 移動等変性と移動不変性: アンチエイリアシングを施すことで、これら重要な幾何学的性質を回復させます。
- 1枚の重み: この制約により、モデルは「物体が少しずれて配置されていても正常である」という概念を、わずか1〜5枚の画像から効率的に学習できるようになります。
5. 驚きの事実4:「解像度」は計算コスト以上の価値をもたらす
解像度を上げることは計算負荷を高めますが、少数学習においてはそのコストを遥かに上回るリターンをもたらします。特に、欠陥サイズが極めて小さい「VisA」データセットにおいて、解像度の向上は劇的な効果を発揮しました。
本研究では、評価指標としてHPROC(Image-AUROCとPixel-AUPRの調和平均)を採用しています。ピクセル精度の評価にAUPRを用いるのは、異常部位が画像全体に対して極めて少ないという「深刻なクラス不均衡」を正しく反映するためです。
解像度の向上(1.0倍を基準とした際)と精度の変化(HPROCの利得)は以下の通りです。
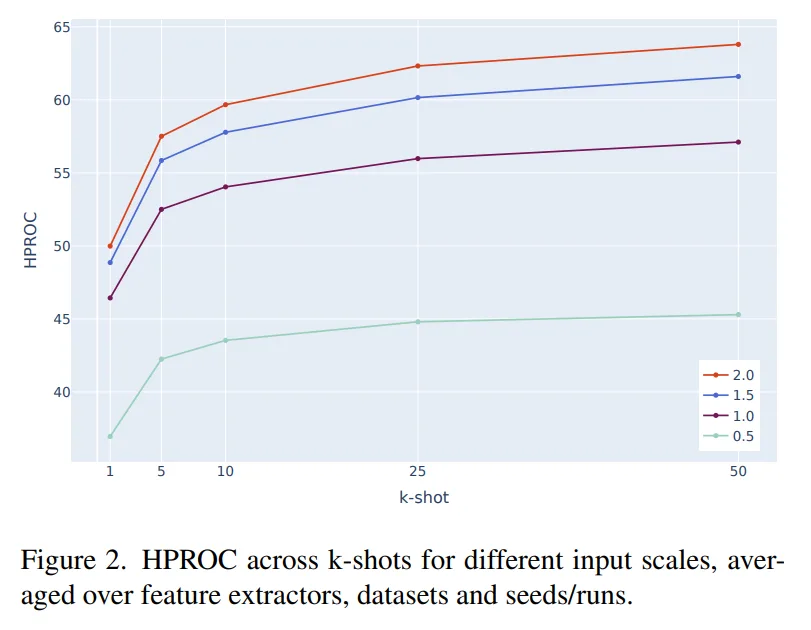
- 0.5倍: 精度が大幅に低下。微細な異常情報が消失。
- 1.5倍: 安定して精度が向上。
- 2.0倍: VisAで+7.5、MVTec ADで+5.0の利得を記録。
特にVisAの欠陥サイズ(中央値0.002)はMVTec AD(0.037)より遥かに小さいため、解像度を2倍に引き上げることが、見逃しを防ぐための「絶対条件」となります。
6. 驚きの事実5:データ拡張(Augmentation)は「諸刃の剣」
データの水増しは少数学習の常套手段ですが、異常検知においてはドメイン知識に基づかない拡張は「毒」になります。

- 回転と反転の罠: トランジスタなどの電子部品では、部品が「逆さま」であること自体が異常です。ここで安易に反転拡張を行うと、AIは致命的な欠陥を「正常」と誤認します。
- 特定の失敗例: MVTec ADにおいて「Sharpen(鮮鋭化)」処理を加えると、逆に精度が低下するケースが確認されました。
- 回転への脆弱性: 最適化されたPatchCoreであっても、MVTec ADの「screw(ネジ)」やVisAの「macaroni2」のように、正常データ自体に強い回転バリエーションが含まれるケースでは苦戦します。
CNNは設計上「回転等変性」を持たないため、現在のPatchCoreは位置のズレには強いものの、回転には依然として弱いという限界が浮き彫りになりました。
7. 結論と展望
本研究は、既存のPatchCoreに「適切な最適化」と「アンチエイリアシングによる幾何学的制約」を加えるだけで、少数学習という難攻不落の課題に対してSOTA(最新の状態)の回答を提示しました。
今後の焦点は、今回の研究で見えてきた「回転への弱さ」を克服することにあります。次世代の異常検知は、「回転等変性CNN(Rotation-Equivariant CNNs)」のような、より強力な物理的制約を組み込んだモデルへと進化していくでしょう。
「わずか数枚のデータだけで、私たちはどこまで完璧な品質管理に近づけるのか?」 その答えは、新しいアルゴリズムの創造だけでなく、私たちがすでに手にしているツールの「隠れたポテンシャル」を引き出す知恵の中にあるのかもしれません。
PodCast
この話をPodCastとして作成しました。以下のリンクをクリックしてみてください。


