時系列異常検知(Time Series Anomaly Detection):過去10年の進化と未来への展望
時系列異常検知:過去10年の進化と未来への展望
本記事は、Paul Boniol、Qinghua Liu、Mingyi Huang、Themis Palpanas、John Paparrizosらによる包括的なレビュー論文「Dive into Time-Series Anomaly Detection: A Decade Review (2024)」の内容を基に作成しています。
はじめに
皆さんは日々の生活の中で、「時系列データ」という言葉を意識することはありますか?実は、私たちの身の回りには、この時系列データが溢れています。例えば、スマートウォッチが記録する心拍数、スマートフォンの株価アプリに表示される株価の変動、天気予報の気温の変化、IoTデバイスが収集する工場の機械の稼働状況など、これらすべてが時間を追って記録されたデータ、つまり「時系列データ」なのです。
このような膨大な時系列データを分析することは、天文学、生物学、経済学、医学、工学、環境科学、さらにはサイバーセキュリティや金融市場、法執行機関といった幅広い分野で不可欠な活動となっています。これらのデータから、通常とは異なるパターン、つまり「異常(Anomalies)」を検知することが、「時系列異常検知(Time Series Anomaly Detection)」と呼ばれる技術です。
なぜ異常検知がそれほど重要なのでしょうか?それは、異常が単なる「ノイズ」や「測定誤差」である場合もあれば、「故障」「不正行為」「サイバー攻撃」「予期せぬ行動変化」といった、私たちにとって非常に重要な意味を持つイベントを示していることがあるからです。例えば、心電図(ECG)データにおける期外収縮の検出は、患者の健康状態を監視し、早期警告を出すために役立ちます。エンジンのディスク回転の異常やスペースシャトルのマロッタバルブの異常なサイクルを検知することは、機械の故障を予測し、予期せぬ停止を防ぐ上で非常に重要です。このように、異常検知は、システムのパフォーマンスを最適化し、セキュリティを強化し、リスクを軽減し、重要なイベントを早期に警告するために不可欠な技術なのです。
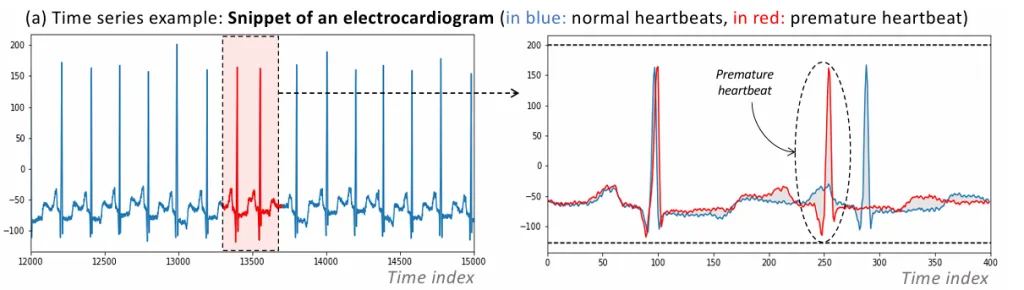
しかし、この異常検知タスクには大きな課題があります。それは、異常なデータが、正常なデータに比べて圧倒的に少ないという特徴です 。めったに起こらないイベントを正確に特定することは、通常の機械学習タスクとは異なるアプローチを必要とします。
この記事では、近年急速に進化を遂げている時系列異常検知の分野について、特に過去10年のトレンドに焦点を当て、その仕組み、主要なアルゴリズム、評価方法、そして今後の展望について、機械学習の専門家でなくても分かりやすく解説していきます。
異常とは何か?時系列データの特異な性質
時系列データにおける「異常」とは、「正常な振る舞いや、これまでに観測されたデータに基づく期待される挙動に適合しないデータポイントやデータポイントのグループ」と定義されます。学術的には、「外れ値(outliers)」「新規性(novelties)」「例外(exceptions)」「特異点(peculiarities)」「逸脱(deviants)」「不調和(discords)」といった様々な言葉で表現されることもあります。
異常は、大きく分けて2つの意味合いを持つことがあります。
- ノイズまたは誤ったデータ:
- これはデータ分析を妨げる「望ましくないデータ」であり、データクリーニングの段階で削除または修正されるべきものです。例えば、センサーの通信エラーや一時的な測定器の誤作動などがこれにあたります。
- 関心のある実際のデータ:
- これは「珍しいけれど興味深い現象」を示すデータであり、故障や振る舞いの変化といった、その後の分析の基礎となる意味のあるイベントを特定するものです。金融市場での不正取引の検出や、ウェブサイトの急激なアクセス数の増加(または減少)などがこの例です。この場合、異常そのものが分析の対象となります。
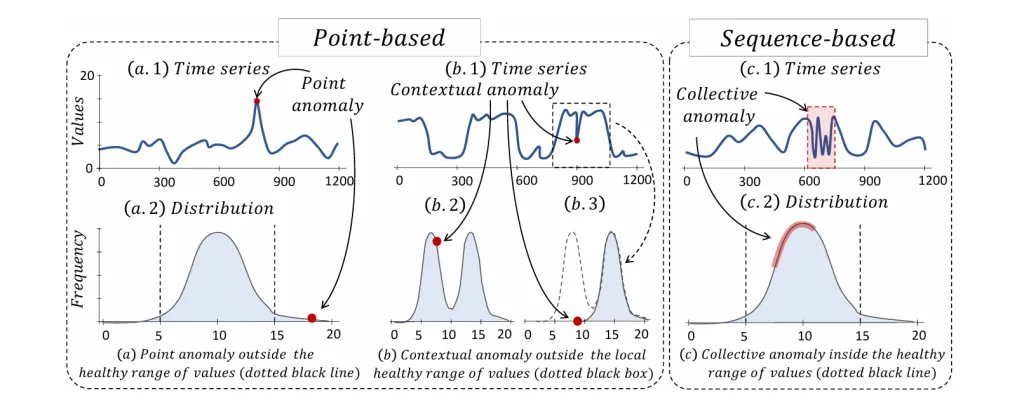
時系列データにおける異常は、その発生形態によってさらに細かく分類されます。
-
ポイント異常 (Point Anomalies):
- 特定の瞬間のデータポイントが、他のデータポイントから著しく逸脱している場合です。例えば、ウェブサイトへのアクセス数が突発的に急増する「スパイク」現象などがこれに該当します。個々のデータ点だけを見ても異常と判断できることが多いです。
-
文脈的異常 (Contextual Anomalies):
- データポイント自体は通常の範囲内にあるものの、特定の文脈(例:時間帯や季節)において異常な挙動を示す場合です。例えば、夜間のアクセス数が通常の範囲内でも、それが真夜中であれば異常と判断されるようなケースです。
-
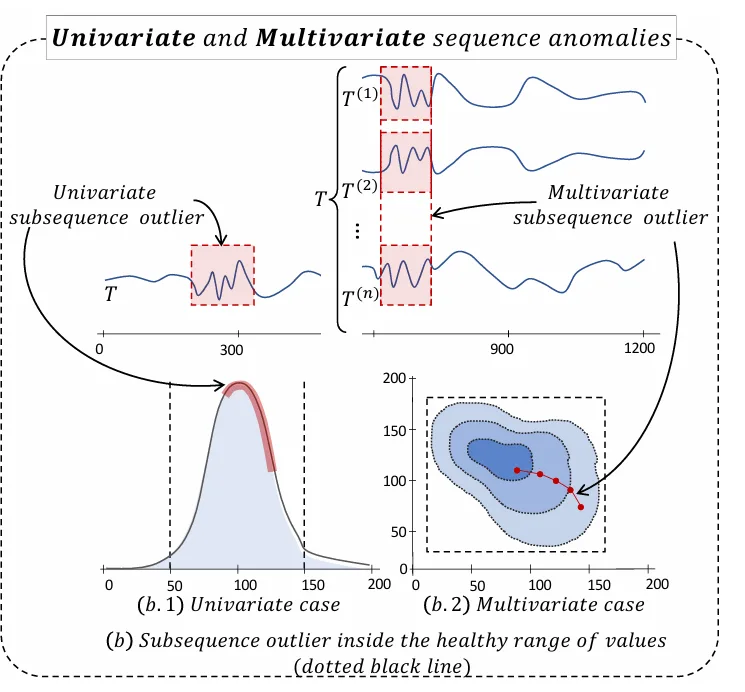
集団異常 (Collective Anomalies):
- 個々のデータポイントは正常に見えるかもしれませんが、連続するデータポイントのシーケンス(サブシーケンス)全体として異常なパターンを示す場合です。例えば、心電図の波形が通常の心拍とは異なる形状を示す場合などがこれにあたります。この場合、個々の点だけを考慮しても異常を検出することはできません。
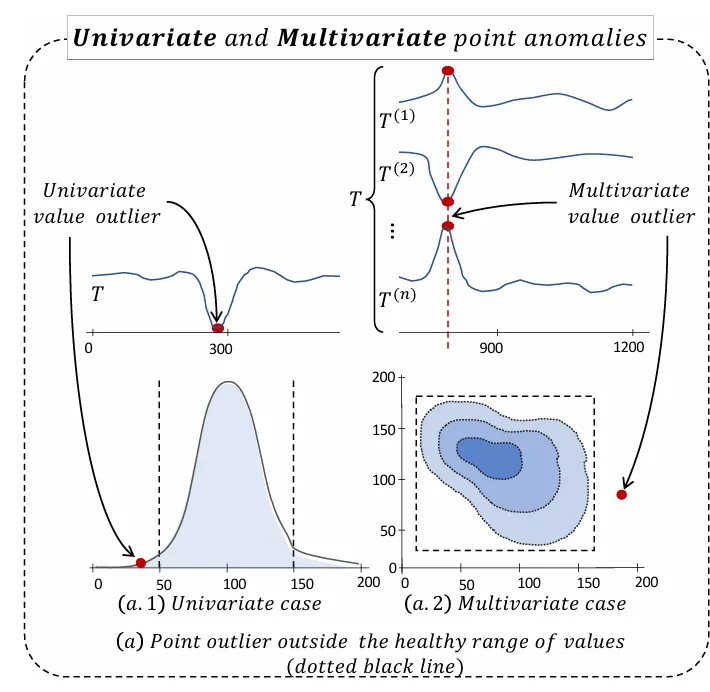
さらに、時系列データは、測定されている変数の数によっても区別されます。
-
単変量(Univariate)時系列:
- 単一の変数(例:気温や株価の終値)の値を時系列で記録したものです。異常はその単一の変数に基づいて検出されます。
-
多変量(Multivariate)時系列:
- 複数の変数(例:気温、湿度、気圧といった複数の気象データや、複数のセンサーからのデータ)を同時に記録したものです。ある1つの変数の値だけを見ると正常に見えても、複数の変数の間の関係性全体として異常が検出されることがあります。
異常検知のパイプライン
時系列データは、サイバーセキュリティ、金融、医療など、幅広い分野で活用されていますが、その中に潜む「異常(アノマリー)」を特定することは非常に重要です。異常とは、通常のパターンや期待される挙動から著しく逸脱したデータポイントやその集まりを指します。これらは単なるノイズの場合もあれば、故障や不正などの重要な意味を持つイベントを示すこともあります。
時系列データの複雑さから、これらの異常を効率的かつ正確に検出するためには、体系的なアプローチが必要です。そこで用いられるのが、時系列異常検知パイプラインです。このパイプラインは、異常検知プロセスを以下の4つの主要なステップに分解することで、さまざまなアルゴリズムの比較や理解を容易にします。
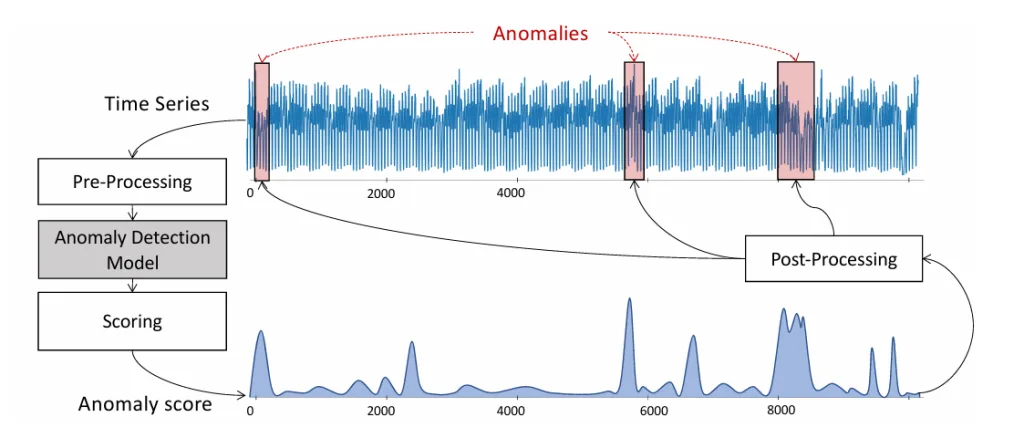
- データ前処理 (Data Pre-processing) この最初のステップでは、生の時系列データを分析に適した形に変換します。多くの場合、スライディングウィンドウアプローチを用いて、時系列データを一定の長さの「サブシーケンス」に分割し、それぞれを多次元の点として扱います。これに加えて、統計的特徴量の抽出、機械学習モデルの構築、ニューラルネットワークの準備など、さまざまな追加処理が行われることがあります。例えば、データのスケールを均一にするためのZ-正規化や、季節性を取り除くためのSTL分解などが含まれます。
- 検知手法 (Detection Method) 前処理されたデータに対して、具体的な異常検知アルゴリズムが適用されます。このステップでは、データ間の距離を計算したり、分類のための境界線を設定したり、生成されたサブシーケンスと元のサブシーケンスを比較したりするなど、様々な方法が用いられます。距離ベース、密度ベース、予測ベースといった多様なカテゴリのアルゴリズムがこの段階で機能します。
- スコアリング (Scoring) 検知手法の結果は、各データポイントやサブシーケンスの「異常スコア」という単一の実数値に変換されます。このスコアは、そのデータがどれだけ異常であるかを示します。最終的に、元の時系列と同じ長さの異常スコア時系列が生成されます。例えば、予測誤差の大きさや、近傍からの孤立度などがスコアとして利用されます。
- 後処理 (Post-processing) 最後のステップでは、生成された異常スコア時系列を分析し、実際に異常なポイントや期間を特定します。一般的には、閾値が設定され、この閾値を超えたスコアを持つポイントが異常としてマークされます。閾値の設定方法も、固定値や統計的手法、あるいは適応的な動的閾値など、様々なアプローチが存在します。
このパイプラインによって、複雑な時系列データにおける異常検知プロセスが構造化され、それぞれのステップがどのような役割を果たすかが明確になります。
異常検知アルゴリズムの多様なアプローチ
時系列異常検知は、前述の通り「異常データが少ない」という特徴を持っています。そのため、多くのアルゴリズムは、「正常なデータがどのようなパターンや特徴を持っているか」を学習し、その正常な振る舞いから大きく逸脱するものを異常とみなすというアプローチを取ります。
このアプローチは、主に3つのカテゴリに分けられます。
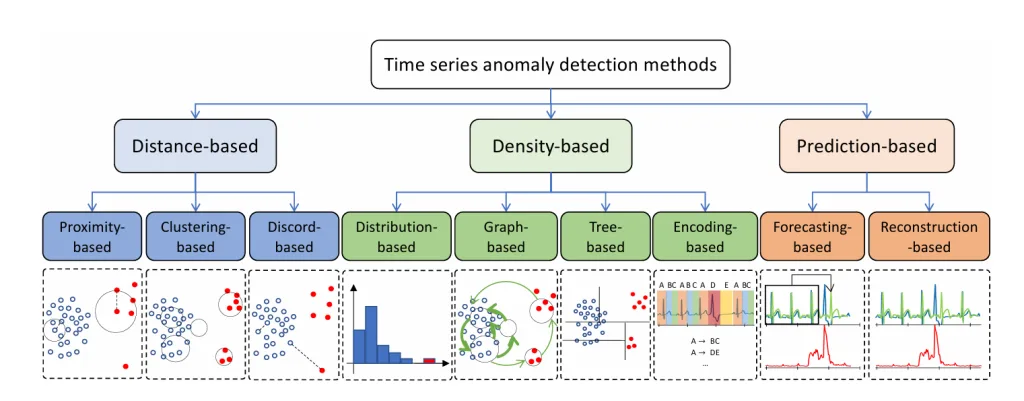
- 距離ベースの手法 (Distance-based Methods):
- データポイントやサブシーケンス間の「距離」や「類似性」に基づいて異常を特定します。「ご近所さんから離れているほど異常」という考え方です。
- 近接度ベース (Proximity-based):
- 特定のデータポイントが、その周囲の「ご近所さん」からどれだけ孤立しているかを測ります。例えば、K-th Nearest Neighbor (KNN) は、あるデータポイントからK番目に近い点までの距離を異常スコアとし、この距離が大きいほど異常と見なします。Local Outlier Factor (LOF) は、そのデータポイントの周囲の密度と、ご近所さんの密度を比較することで、どれだけ孤立しているかを測り、その度合いを異常スコアとします。「近所付き合いが少ない人は目立つ」という直感に基づいています。
- クラスタリングベース (Clustering-based):
- データをいくつかの「グループ(クラスター)」に分け、どのグループにも属さない、または小さなグループに属するものを異常と判断します。「グループに馴染めないものは異常」という考え方です。代表的なアルゴリズムに K-means や DBSCAN があります。DBSCANは、データ点を「コアポイント(密集している点)」「ボーダーポイント(境界にある点)」「異常(どこにも属さない点)」の3つに分類することで異常を検出します。
- 不一致ベース (Discord-based):
- 時系列の中で、「最も変わり者」なサブシーケンス、つまりその最近傍との距離が最も大きいサブシーケンスを特定します。例えば、Matrix Profile は、時系列内のすべてのサブシーケンスについて、その最近傍との距離を記録した「メタ時系列」を生成し、その値が最も高い部分を異常として検出します。
- 密度ベースの手法 (Density-based Methods):
- データポイントやサブシーケンスの「密度」や「分布の形状」に基づいて異常を特定します。
- 分布ベース (Distribution-based):
- データがどのような統計的な分布をしているかを学習し、その分布から外れるものを異常と見なします。例えば、One-Class Support Vector Machine (OCSVM) は、正常なデータだけを学習して、それらを「原点」から分離する最適な境界を見つけます。この境界から遠く離れたデータポイントは異常と判断されます。
- ツリーベース (Tree-based):
- データをツリー構造に分割し、異常なデータポイントは正常なデータポイントよりもツリーの浅い位置で早く「隔離」できるという考え方に基づきます。Isolation Forest (IForest) がその代表で、「異常なデータは少数で異なる」という事実を利用し、効率的に異常を特定します。
- エンコーディングベース (Encoding-based):
- 時系列データを、より低次元の「潜在空間」や、別のデータ構造(例えば、記号のシーケンスやグラフ)に変換(エンコード)します。このエンコードされた表現から、異常なデータポイントを検出します。例えば、Principal Component Analysis (PCA) は、データの主要なパターンを抽出し、そのパターンから大きく逸脱するものを異常と見なします。
- 予測ベースの手法 (Prediction-based Methods):
- モデルが「正常な状態であれば次に何が起こるか」を予測するように学習し、実際のデータと予測が大きく異なる場合にそれを異常と見なします。
- 予測ベース (Forecasting-based):
- 過去のデータに基づいて、未来の値を予測します。そして、「予測された値」と「実際の値」との間に大きな誤差があれば、それを異常と判断します。例えば、Long Short-Term Memory (LSTM) や Gated Recurrent Unit (GRU) のような深層学習モデルは、時系列データの複雑なパターンを学習し、正常なデータで訓練されたモデルは、異常なデータに遭遇すると予測が困難になり、大きな予測誤差を生じます。
- 再構築ベース (Reconstruction-based):
- モデルが入力データを圧縮(エンコード)し、それを再度元の形に復元(デコード)するように学習します。正常なデータはうまく復元できますが、異常なデータはうまく復元できず、大きな「再構築誤差」が生じます。この誤差を異常スコアとして利用します。
- オートエンコーダー (Autoencoder: AE) はこの典型的なモデルです。さらに、Generative Adversarial Network (GAN) もこのカテゴリに属し、新しいデータを生成する「生成器」と、それが本物か偽物かを識別する「識別器」の2つのネットワークが競い合うことで、正常なデータのパターンを学習します。異常なデータは、生成器がうまく生成できなかったり、識別器が「偽物」と判断したりすることで検出されます。
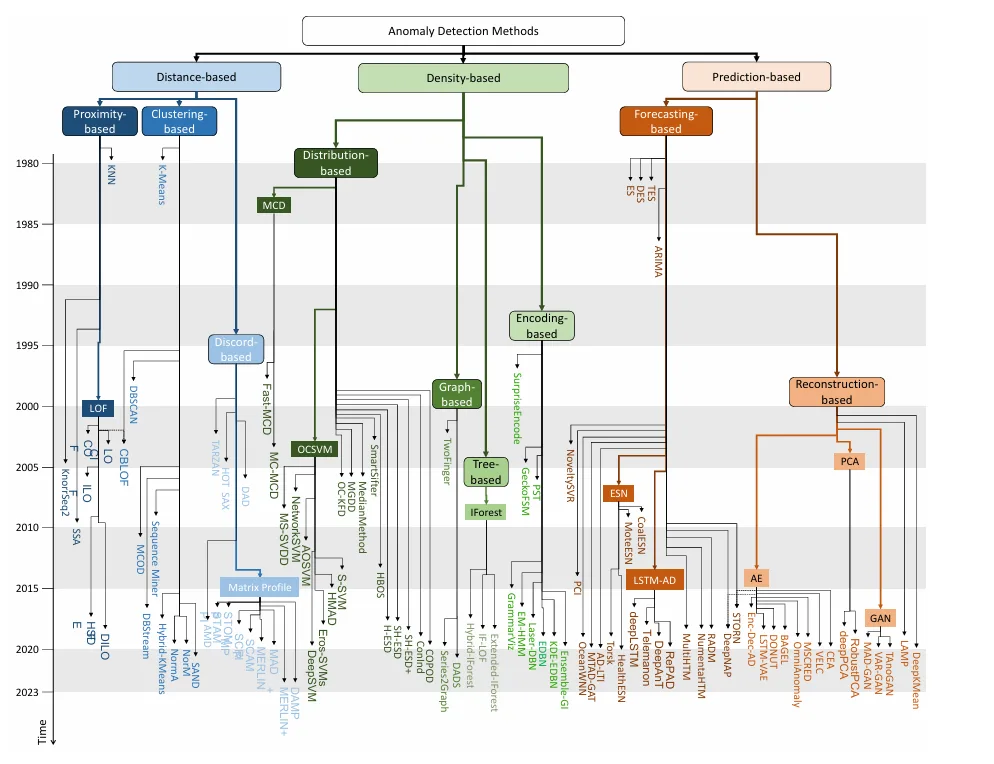
異常検知の「過去10年」のトレンド
時系列異常検知の研究は、特に2016年以降、論文発表数の増加が顕著であり、この分野への学術的な関心が急速に高まっていることが見て取れます。
この成長の大部分は、予測ベースの手法、特にLSTMやオートエンコーダーといった深層学習ベースのアプローチによって牽引されています。これは、画像認識など他の分野で深層学習が大きな成功を収めた影響が時系列データにも波及したこと、そしてTensorFlowやPyTorchのようなオープンソースの深層学習ライブラリの登場により、これらの汎用的な深層学習手法を時系列データに適用することが容易になったことが背景にあります。
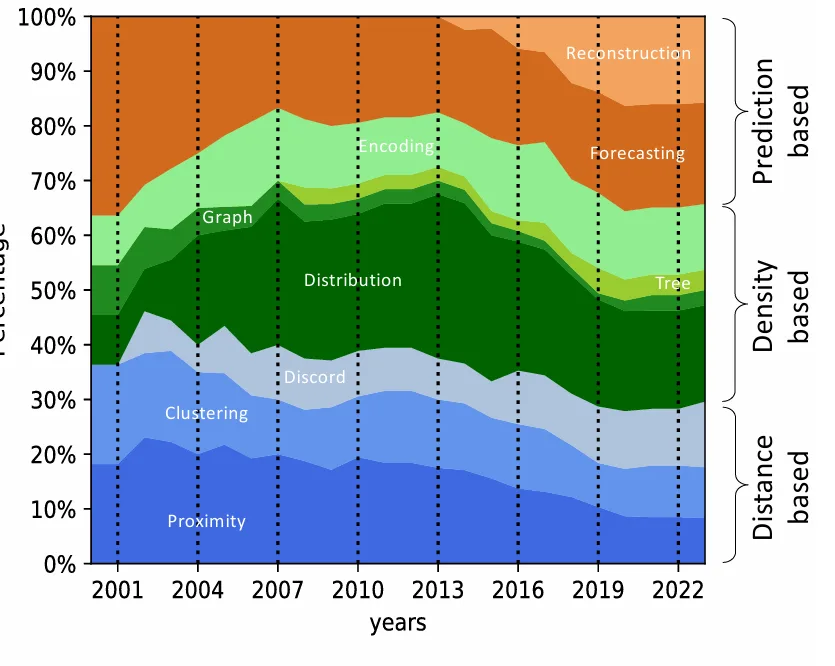
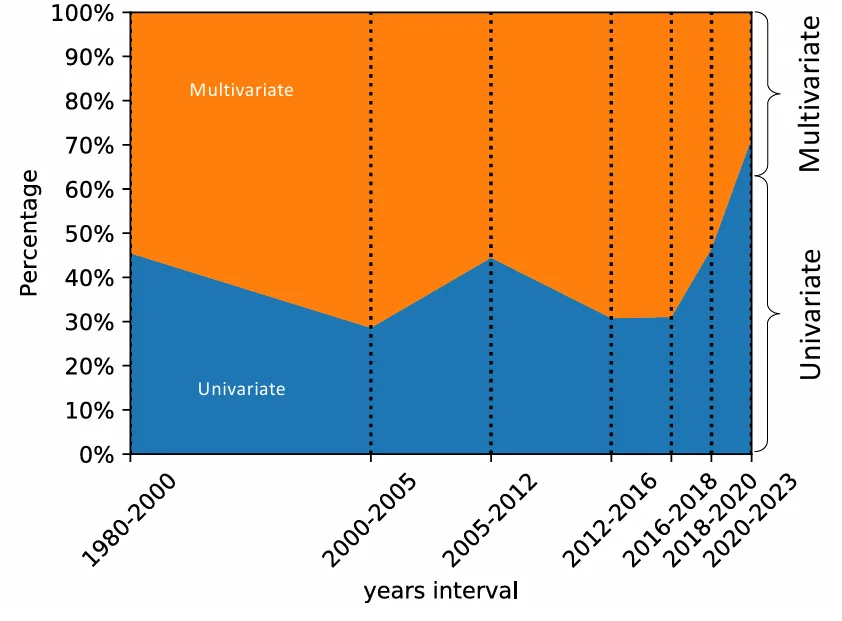
興味深いことに、2016年以前は多変量時系列の異常検知に焦点を当てた手法が多かったのに対し、直近数年間では単変量時系列向けの手法が大幅に増加しています。これは、多変量時系列における集団異常(シーケンス異常)の定義と検出がより複雑であるため、研究の焦点が移っている可能性を示唆しています。
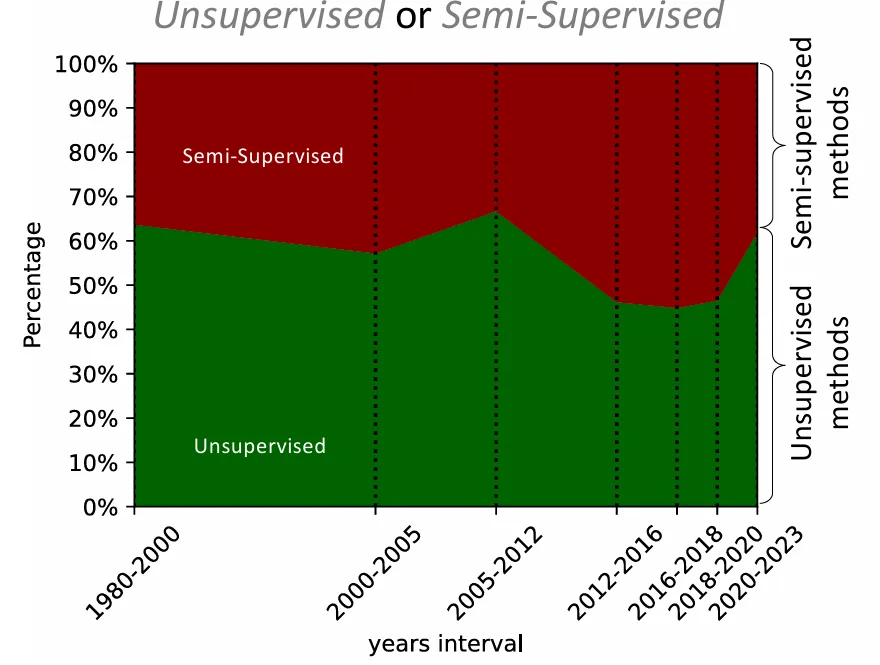
また、異常検知の手法は、利用するラベル情報の種類によって「教師なし(Unsupervised)」「半教師あり(Semi-supervised)」「教師あり(Supervised)」に分類されます。異常データが少ないという特性から、教師なしや半教師ありの手法が主流であり、特に半教師ありの手法は「正常な振る舞いの例」のみを学習データとして使用します 。過去には教師なし手法が多かったものの、近年では半教師あり手法も増加傾向にあります。
アルゴリズムを測る物差し:評価データセットと指標
どんなに優れた異常検知アルゴリズムでも、「万能な解決策」というものは存在しません。特定のデータセットや異常タイプでは高性能を発揮しても、別の状況ではうまくいかないことがあります。そのため、アルゴリズムの性能を公平かつ包括的に評価するためには、多様な特性を持つデータセット群(ベンチマーク)と、適切な評価指標が不可欠です。
既存のベンチマークデータセット
これまで、時系列異常検知の評価のために多くのベンチマークが提案されてきました。
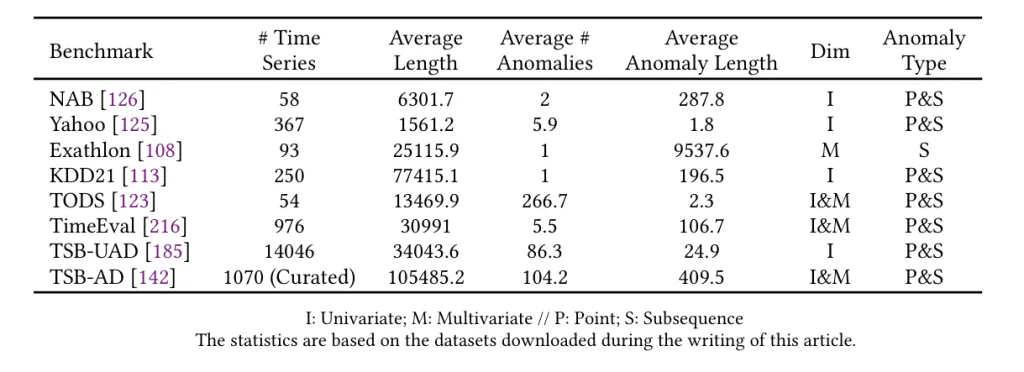
- NAB (Numenta Anomaly Benchmark):
- 58個のラベル付きリアルワールドおよび人工時系列データから構成され、主にストリーミングデータのリアルタイム異常検知に焦点を当てています。AWSサーバーメトリクス、オンライン広告のクリック率、Twitterでの企業言及など、多様なドメインをカバーしています。
- Yahoo (S5 - Labeled Anomaly Detection Dataset):
- Yahooの実際のプロダクションシステムからのトラフィックに由来する、リアルおよび合成時系列データのコレクションです。
- Exathlon:
- 高次元時系列データにおける説明可能な異常検知のために提案されました。Apache Sparkクラスターでの大規模ストリーム処理ジョブの実際のデータトレースに基づいています。
- KDD21 (UCR Anomaly Archive):
- 医学、スポーツ、宇宙科学など、様々なドメインをカバーする複合データセットです。
- TODS (Time-series Outlier Detection Scenarios):
- ポイントグローバル、パターンコンテクスチュアルなど5つの異常シナリオを含む合成基準を洗練しています。
- TimeEval:
- 非常に異なるドメインからのリアルおよび合成データセットのコレクションを含んでいます。単変量と多変量の両方の時系列データ、およびポイント異常とシーケンス異常の両方を網羅しています。このベンチマークは、71種類の異常検知アルゴリズムを再実装し、967の時系列データセットで評価するという、非常に包括的な研究の基盤となっています。
- TSB-UAD (Time Series Benchmark for Univariate Anomaly Detection):
- 単変量時系列異常検知手法を評価するために設計された、包括的で統一されたベンチマークです。実際の異常を含む公開データセットや、異なる異常タイプを模倣するための11の変換方法を提供する合成データセットが含まれています。
- TSB-AD (Time Series Benchmark for Anomaly Detection):
- これまでで最大のベンチマークであり、1,000個の厳密にキュレーションされた高品質な時系列データセットから構成されます。人間による知覚とモデル駆動型解釈を組み合わせて、信頼性を向上させています。単変量と多変量の両方のケースが含まれており、幅広いリアルワールドシナリオを網羅しています。
しかし、既存のベンチマークには「自明性」「非現実的な異常密度」「誤った正解ラベル(グランドトゥルース)」「run-to-failureバイアス」といった欠陥があるという指摘もされています。これらの課題がある中で、TSB-AD のような新しいベンチマークは、より堅牢で信頼性の高い評価フレームワークを提供しようと努力しています。
評価指標
異常検知アルゴリズムの性能を測るためには、適切な「ものさし」が必要です。評価指標は、大きく分けて閾値(しきい値)ベースと閾値に依存しないものの2種類があります。
-
閾値ベースの評価:
-
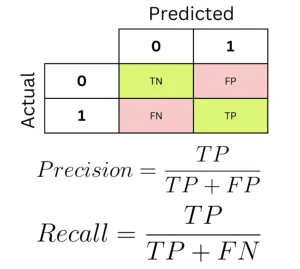
これは、アルゴリズムが出力する「異常スコア」(そのデータ点がどれだけ異常であるかを示す数値)に、ある一定の閾値を設定し、その閾値を超えたら異常、そうでなければ正常と分類する方法です。
-
この分類結果に基づいて、真陽性 (TP: 異常を正しく異常と検出)、真陰性 (TN: 正常を正しく正常と検出)、偽陽性 (FP: 正常を誤って異常と検出)、偽陰性 (FN: 異常を誤って正常と検出) といった指標が計算されます。
-
これらの指標から、精度 (Precision)(検出された異常のうちどれだけが本物か)、再現率 (Recall)(本物の異常のうちどれだけを検出できたか)、そしてこれらを組み合わせたF1スコアなどが計算されます。
-
しかし、閾値ベースの評価は、閾値の設定に敏感で、ノイズの影響を受けやすく、時系列データの時間的な一貫性を考慮しないという課題があります。
-
-
閾値に依存しない評価:
-
アルゴリズムの性能を、すべての可能な閾値設定にわたって要約する指標です。これにより、閾値設定の難しさや、閾値による評価の変動を避けることができます。
-
AUC (Area Under the Curve):
- 最も広く使われる指標で、Receiver Operating Characteristics (ROC) 曲線の下の面積 (AUC-ROC) や、Precision-Recall (PR) 曲線の下の面積 (AUC-PR) があります。ROC曲線は真陽性率(どれだけ異常を検出できたか)と偽陽性率(正常を誤って異常と検出した割合)の関係を示し、PR曲線は精度と再現率の関係を示します。特に異常が少ない「不均衡なデータセット」では、AUC-PRの方がROCよりも有用であるとされています。
-
Range-AUC:
- ポイント異常だけでなく、サブシーケンス異常の評価に対応するために開発されたAUCの拡張です。異常な区間の境界に「バッファ領域」を設けることで、検出のわずかなずれや、ラベル付けのあいまいさを許容します。
-
Volume Under the Surface (VUS):
- Range-AUCの「バッファ長」の設定が評価に影響を与える問題を解決するために考案されました。様々なバッファ長でRange-AUCを計算し、その結果を3次元の曲面として表現し、その体積を評価スコアとします。VUSは、パラメータフリーで閾値に依存せず、堅牢性、識別性、一貫性を持つため、時系列異常検知の評価指標として推奨されています。
-
おわりに
時系列異常検知は、長年にわたる研究が行われてきたにもかかわらず、依然として非常に難しい課題です。様々な研究コミュニティが異なる基本的な概念に基づいて手法を提案してきたため、これまで統一された基準でアルゴリズムを比較評価することが困難でした。しかし、TSB-ADやTimeEvalのような新しい包括的なベンチマークの登場は、この分野の進歩を評価し、特定の課題に適した手法を特定する上で大きく貢献しています。
今後の研究方向としては、以下のような点が挙げられます。
- 単一の共通ベンチマークの確立: コミュニティ全体で合意できる、多様な時系列データと異常タイプを網羅し、ラベルの信頼性が高いベンチマークが引き続き求められています。
- アンサンブル学習とモデル選択、AutoML: 「単一の最良手法は存在しない」というこれまでの評価結果を踏まえ、複数のアルゴリズムを組み合わせるアンサンブル手法や、タスクに応じて最適なモデルを自動で選択・調整するAutoMLのようなアプローチが重要になります。
- より複雑な時系列データへの対応: これまで十分に注目されてこなかった、欠損値を含む時系列、連続しないタイムスタンプを持つ時系列、異種混合の時系列、あるいはストリーミングデータといった、より実世界に近い複雑なデータに対する堅牢で正確な手法の開発が必要です。特に、多変量時系列やストリーミング時系列における異常検知は、さらなる研究が期待されます。
時系列異常検知の分野は、技術の進歩とともにデータ収集技術の発展も相まって、その重要性が増すばかりです。このレビューが、時系列異常検知の基本的な理解を深め、このエキサイティングな分野の今後の発展に貢献するきっかけとなれば幸いです。
参考文献
- Boniol, P., Liu, Q., Huang, M., Palpanas, T., & Paparrizos, J. (2024). Dive into Time-Series Anomaly Detection https://arxiv.org/abs/2412.20512
- Bajaj, A. (2025, April 24). Anomaly Detection in Time Series. Neptune Blog. https://neptune.ai/blog/anomaly-detection-in-time-series
- Schmidl, S., Wenig, P., & Papenbrock, T. (2022). Anomaly Detection in Time Series: A Comprehensive Evaluation. PVLDB, 15(9), 1779-1797. doi:10.14778/3538598.3538602 https://timeeval.github.io/evaluation-paper/ https://github.com/TimeEval/evaluation-paper

