VisAデータセットをMVTecAD型に変換する
VisAデータセットをMVTecAD型に変換する
Anomaly Detectionにおいて、データセットの構造を整備することは後のパイプライン構築や比較分析に大きく影響します。本記事では、VisAデータセットをMVTecADスタイルに変換するためのPythonスクリプトとその背景を詳しく解説します。
1. VisAデータセットについて
VisA(Visual Anomaly dataset)は、Amazonが2022年に公開した異常検知の研究・開発用データセットです。主に以下のような特徴を持っています:
- 対象カテゴリ:日用品から電子部品まで12カテゴリ(例:candle, capsules, pcb1〜4など)
- 異常の種類:破損、汚染、変形など多様な欠陥パターン
- 目的:高精度な異常検知AIの開発と評価
- アノテーション:正常/異常分類に加えて、異常部分のマスク(セグメンテーション)も含まれる
VisAは、Spot-Diffという手法で利用されており、自然な視覚差を学習するベンチマークデータとして高く評価されています。
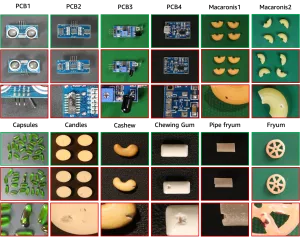
2. VisAデータセットのフォルダ構造
VisAの元データ構造は以下のようになっています:
└─Data
├─Images
│ ├─Anomaly # 異常画像(例:破損)
│ └─Normal # 正常画像
└─Masks
└─Anomaly # 異常画像に対応するマスク画像(異常部分が白く塗られている)ここでは、マスク画像は異常クラスにのみ提供されており、正常画像にはマスクは存在しません。ファイルの拡張子も画像が.jpg、マスクが.pngとなっているのが一般的です。
3. Anomaly Detection業務における標準的なデータ構造(MVTecAD)
多くの異常検知フレームワークでは、MVTec ADの構造を前提として学習/評価を行うため、VisAのような形式をそのまま使うことは困難です。

以下は、MVTecADで標準的に使用されるフォルダ構成です:
├─ground_truth
│ └─bad # 異常画像のマスク(白が異常部分)
├─test
│ ├─bad # 異常画像
│ └─good # 正常画像
└─train
└─good # 正常画像(学習用)この構造では、trainは正常のみ、testに正常・異常、ground_truthは異常画像のマスク、という明確な分離がなされています。PyTorchやanomalibなど多くのフレームワークで、この構造が事実上のデファクトスタンダードになっています。
4. VisAをMVTecAD型に変換するPythonスクリプト
4.1 ベースコードと改変内容
本記事のスクリプトは、Amazon公式の spot-diff に含まれる変換コードを元に、以下の点を改変しました:
- split_type='1cls' のみに限定:2クラス学習(2cls_highshot/fewshot)は省略
- 画像ファイルをjpg→pngに統一:マスクとフォーマットを揃えるため
- マスクの保存名を統一:
000_mask.pngのようにリネーム - マスク画像の2値化処理:元画像がuint8でない場合の不整合を防ぐため
4.2 スクリプト全文とコメント付き解説
import os
import shutil
import csv
from PIL import Image
import numpy as np
# 指定されたパスが存在しない場合、ディレクトリを作成する関数
def _mkdirs_if_not_exists(path):
if not os.path.exists(path):
os.makedirs(path)
# メイン処理関数
# VisAの元データを、MVTecAD形式の構造に変換して保存する
def prepare_data(data_folder='./VisA/', save_folder='./VisA_pytorch/', split_file='./split_csv/1cls.csv'):
# 対象とする12カテゴリ(データセット名)
data_list = ['candle', 'capsules', 'cashew', 'chewinggum', 'fryum',
'macaroni1', 'macaroni2', 'pcb1', 'pcb2', 'pcb3', 'pcb4', 'pipe_fryum']
# 各カテゴリごとに保存先ディレクトリ(train/test/mask)を準備
for data in data_list:
train_folder = os.path.join(save_folder, data, 'train')
test_folder = os.path.join(save_folder, data, 'test')
mask_folder = os.path.join(save_folder, data, 'ground_truth')
train_img_good_folder = os.path.join(train_folder, 'good')
test_img_good_folder = os.path.join(test_folder, 'good')
test_img_bad_folder = os.path.join(test_folder, 'bad')
test_mask_bad_folder = os.path.join(mask_folder, 'bad')
# 保存先フォルダを作成(存在しない場合)
_mkdirs_if_not_exists(train_img_good_folder)
_mkdirs_if_not_exists(test_img_good_folder)
_mkdirs_if_not_exists(test_img_bad_folder)
_mkdirs_if_not_exists(test_mask_bad_folder)
# 分割CSVファイルを読み込む
with open(split_file, 'r') as file:
csvreader = csv.reader(file)
header = next(csvreader) # ヘッダー行をスキップ
for row in csvreader:
object_name, set_type, label, image_path, mask_path = row
label = 'good' if label == 'normal' else 'bad'
# 画像の読み込みと拡張子変換(jpg→png)
img_src_path = os.path.join(data_folder, image_path)
image = Image.open(img_src_path).convert("RGB")
base_name = os.path.splitext(os.path.basename(image_path))[0] # ファイル名のベース部分(拡張子除く)
image_name = base_name + '.png'
img_dst_path = os.path.join(save_folder, object_name, set_type, label, image_name)
image.save(img_dst_path, format='PNG')
print(f"{object_name}:{img_dst_path}")
# 異常画像のマスク保存(test/badのみ)
if set_type == 'test' and label == 'bad':
msk_src_path = os.path.join(data_folder, mask_path)
mask_name = base_name + '_mask.png'
msk_dst_path = os.path.join(save_folder, object_name, 'ground_truth', label, mask_name)
# マスク画像を2値化(異常領域=255)
mask = Image.open(msk_src_path)
mask_array = np.array(mask)
mask_array[mask_array != 0] = 255
Image.fromarray(mask_array.astype(np.uint8)).save(msk_dst_path)
print(f"{object_name}:{msk_dst_path}")
# 実行時のパラメータ指定と関数呼び出し
if __name__ == '__main__':
prepare_data(
data_folder=r'C:/Users/kotai/Downloads/VisA_20220922',
save_folder=r'C:/Datasets/VisA',
split_file=r'1cls.csv'
)5. なぜマスクを255に変換するのか?
VisAのマスク画像は .png 形式ですが、保存形式が uint8(8ビット整数)とは限らず、uint16 や float で保存されていることがあります。そのため、異常領域が 255 ではなく 1 や 128 などで表現されている可能性があります。これを PyTorch 等の2値マスク形式に整えるには、異常部位を一律で255に置き換える処理が必要です。
PyTorchなどでバイナリマスクとして扱うには:
- 0 → 異常なし
- 255 → 異常あり
という明快な2値化が必要です。そのため、
mask_array[mask_array != 0] = 255の処理によって、異常部分をすべて255に統一しています。
結論
VisAのような高品質なデータセットを、少しの前処理で現行のAIフレームワークに適合させることで、よりスムーズな実験・評価が可能になります。
本記事のコードを参考に、他の独自データセットでもMVTecAD型への変換が行えるようになることを目指してください。
参考資料
https://github.com/amazon-science/spot-diff?tab=readme-ov-file

